前端技术
HTML
CSS
Javascript
前端框架和UI库
VUE
ReactJS
AngularJS
JQuery
NodeJS
JSON
Element-UI
Bootstrap
Material UI
服务端和客户端
Java
Python
PHP
Golang
Scala
Kotlin
Groovy
Ruby
Lua
.net
c#
c++
后端WEB和工程框架
SpringBoot
SpringCloud
Struts2
MyBatis
Hibernate
Tornado
Beego
Go-Spring
Go Gin
Go Iris
Dubbo
HessianRPC
Maven
Gradle
数据库
MySQL
Oracle
Mongo
中间件与web容器
Redis
MemCache
Etcd
Cassandra
Kafka
RabbitMQ
RocketMQ
ActiveMQ
Nacos
Consul
Tomcat
Nginx
Netty
大数据技术
Hive
Impala
ClickHouse
DorisDB
Greenplum
PostgreSQL
HBase
Kylin
Hadoop
Apache Pig
ZooKeeper
SeaTunnel
Sqoop
Datax
Flink
Spark
Mahout
数据搜索与日志
ElasticSearch
Apache Lucene
Apache Solr
Kibana
Logstash
数据可视化与OLAP
Apache Atlas
Superset
Saiku
Tesseract
系统与容器
Linux
Shell
Docker
Kubernetes
站内搜索
用于搜索本网站内部文章,支持栏目切换。
关于这篇文章,其他用户还搜了这些:
名词解释
作为当前文章的名词解释,仅对当前文章有效。
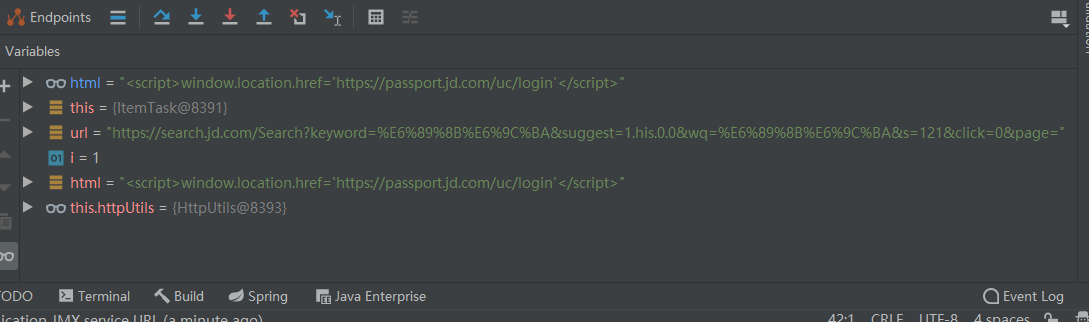
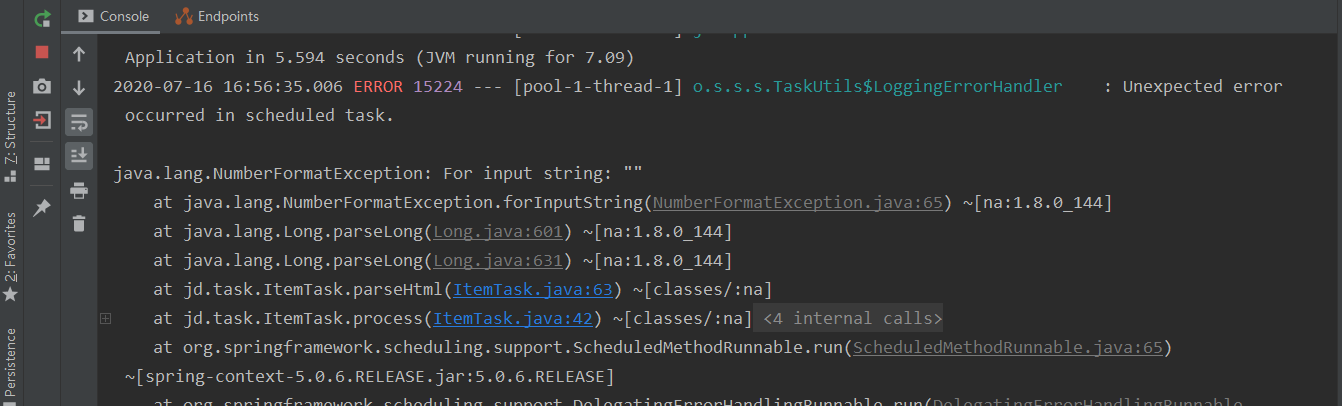
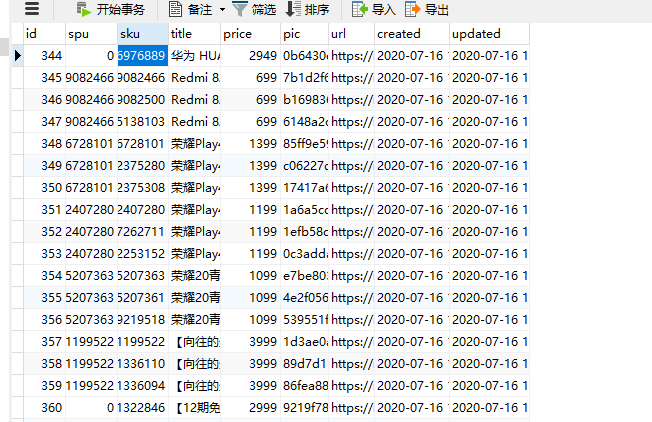
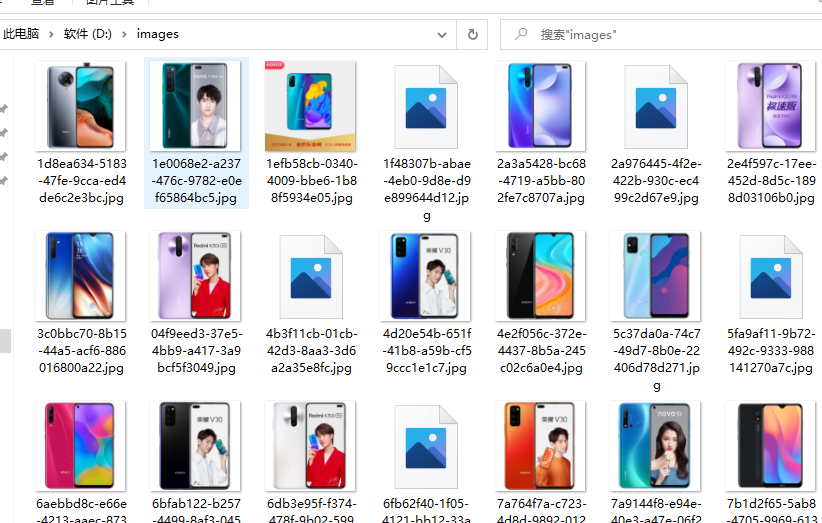
Java爬虫技术:Java爬虫技术是一种利用Java编程语言实现的网络数据抓取工具,通过模拟用户浏览器行为发送HTTP请求,获取网页HTML内容,并进一步解析、抽取和处理所需信息的技术手段。在本文中,作者学习并实践了Java爬虫技术,用于从京东商城抓取手机类商品的数据。
SpringBoot框架:SpringBoot是由Pivotal团队开发的一款开源Java应用程序框架,它简化了Spring应用的初始搭建以及开发过程,提供了一种快速构建独立、生产级别的基于Spring框架的应用程序的方式。在文中,项目采用SpringBoot框架进行搭建,结合JPA(Java Persistence API)实现对爬取数据的持久化存储管理。
JPA(Java Persistence API):JPA是Java平台上的一个规范,为Java开发者提供了对象关系映射(ORM)的功能,使开发者可以使用面向对象的方式来操作数据库。在文章的场景下,JPA被应用于SpringBoot项目中,用以简化数据库操作,将爬取的商品数据自动映射到实体类,并通过ORM方式方便地与数据库进行交互和数据持久化。
HttpClient:Apache HttpClient是一个强大的Java库,用于执行HTTP协议相关的客户端功能,如GET、POST等请求,获取HTTP响应结果。在本文的爬虫项目中,HttpClient被用来发起对京东页面的HTTP请求,获取商品列表页面的HTML源码。
Jsoup:Jsoup是一个基于Java的HTML解析器,它可以非常方便地提取和操作HTML文档中的数据,支持CSS选择器来查找元素。在该篇文章的爬虫实践中,Jsoup用于解析从京东页面获取的HTML内容,从中提取出商品SPU、SKU、价格、标题、图片链接等具体信息。
延伸阅读
作为当前文章的延伸阅读,仅对当前文章有效。
在学习Java爬虫技术并实践于京东商品信息抓取的过程中,可能会遇到各种实际问题,如网页结构变化、登录验证机制、数据解析异常等。这些问题的解决不仅有助于提升个人编程能力,更对了解反爬机制与合法合规的数据抓取有重要启示作用。
近期,关于网络爬虫技术的法律边界和道德规范引起了广泛关注。2022年,中国最高人民法院发布了《关于审理使用人脸识别技术处理个人信息相关民事案件适用法律若干问题的规定》,其中强调了在数据抓取过程中应尊重用户隐私权和个人信息安全。这意味着,在开发爬虫项目时,除了关注技术实现外,开发者还需严格遵守相关法律法规,确保数据来源的合法性。
另外,各大电商平台针对爬虫行为不断升级反爬策略,例如采用动态加载、加密参数、验证码等方式防止非授权抓取。在这种情况下,学习和研究如何通过模拟登录、设置合适的请求头(如User-Agent)、以及运用更高级的网络代理、IP池等手段绕过反爬机制,成为爬虫开发者必须掌握的技术要点。
与此同时,对于页面数据解析环节,诸如Jsoup这样的HTML解析库虽然强大易用,但在面对复杂多变的网页结构时,可能需要结合XPath或CSS选择器等更多工具进行精细化处理。此外,随着JavaScript渲染技术在现代网页中的广泛应用,传统的HTTP请求方式已无法满足部分动态加载内容的抓取需求,因此引入Selenium、Puppeteer等无头浏览器工具进行交互式爬虫开发已成为一种趋势。
总之,在深入学习和应用Java爬虫技术的同时,我们应当紧跟技术发展潮流,并时刻保持对法律、伦理及技术挑战的关注,以确保我们的爬虫项目既高效又合规。
近期,关于网络爬虫技术的法律边界和道德规范引起了广泛关注。2022年,中国最高人民法院发布了《关于审理使用人脸识别技术处理个人信息相关民事案件适用法律若干问题的规定》,其中强调了在数据抓取过程中应尊重用户隐私权和个人信息安全。这意味着,在开发爬虫项目时,除了关注技术实现外,开发者还需严格遵守相关法律法规,确保数据来源的合法性。
另外,各大电商平台针对爬虫行为不断升级反爬策略,例如采用动态加载、加密参数、验证码等方式防止非授权抓取。在这种情况下,学习和研究如何通过模拟登录、设置合适的请求头(如User-Agent)、以及运用更高级的网络代理、IP池等手段绕过反爬机制,成为爬虫开发者必须掌握的技术要点。
与此同时,对于页面数据解析环节,诸如Jsoup这样的HTML解析库虽然强大易用,但在面对复杂多变的网页结构时,可能需要结合XPath或CSS选择器等更多工具进行精细化处理。此外,随着JavaScript渲染技术在现代网页中的广泛应用,传统的HTTP请求方式已无法满足部分动态加载内容的抓取需求,因此引入Selenium、Puppeteer等无头浏览器工具进行交互式爬虫开发已成为一种趋势。
总之,在深入学习和应用Java爬虫技术的同时,我们应当紧跟技术发展潮流,并时刻保持对法律、伦理及技术挑战的关注,以确保我们的爬虫项目既高效又合规。
知识学习
实践的时候请根据实际情况谨慎操作。
随机学习一条linux命令:
chown user:group file
- 改变文件的所有者和组。
推荐内容
推荐本栏目内的其它文章,看看还有哪些文章让你感兴趣。
2023-02-18
2023-08-07
2023-09-10
2024-01-12
2023-01-11
2023-10-22
2023-01-13
2023-10-29
2024-01-09
2023-08-26
2023-01-02
2023-05-10
历史内容
快速导航到对应月份的历史文章列表。
随便看看
拉到页底了吧,随便看看还有哪些文章你可能感兴趣。
时光飞逝
"流光容易把人抛,红了樱桃,绿了芭蕉。"