前端技术
HTML
CSS
Javascript
前端框架和UI库
VUE
ReactJS
AngularJS
JQuery
NodeJS
JSON
Element-UI
Bootstrap
Material UI
服务端和客户端
Java
Python
PHP
Golang
Scala
Kotlin
Groovy
Ruby
Lua
.net
c#
c++
后端WEB和工程框架
SpringBoot
SpringCloud
Struts2
MyBatis
Hibernate
Tornado
Beego
Go-Spring
Go Gin
Go Iris
Dubbo
HessianRPC
Maven
Gradle
数据库
MySQL
Oracle
Mongo
中间件与web容器
Redis
MemCache
Etcd
Cassandra
Kafka
RabbitMQ
RocketMQ
ActiveMQ
Nacos
Consul
Tomcat
Nginx
Netty
大数据技术
Hive
Impala
ClickHouse
DorisDB
Greenplum
PostgreSQL
HBase
Kylin
Hadoop
Apache Pig
ZooKeeper
SeaTunnel
Sqoop
Datax
Flink
Spark
Mahout
数据搜索与日志
ElasticSearch
Apache Lucene
Apache Solr
Kibana
Logstash
数据可视化与OLAP
Apache Atlas
Superset
Saiku
Tesseract
系统与容器
Linux
Shell
Docker
Kubernetes


站内搜索
用于搜索本网站内部文章,支持栏目切换。
关于这篇文章,其他用户还搜了这些:
名词解释
作为当前文章的名词解释,仅对当前文章有效。
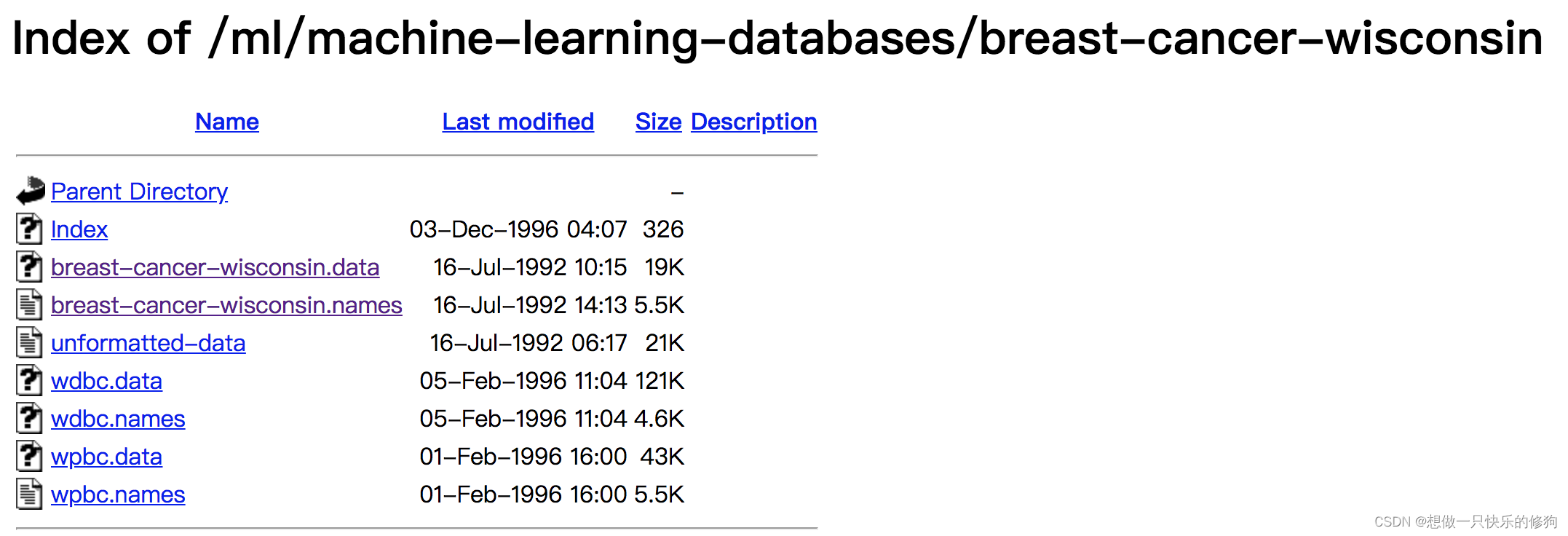
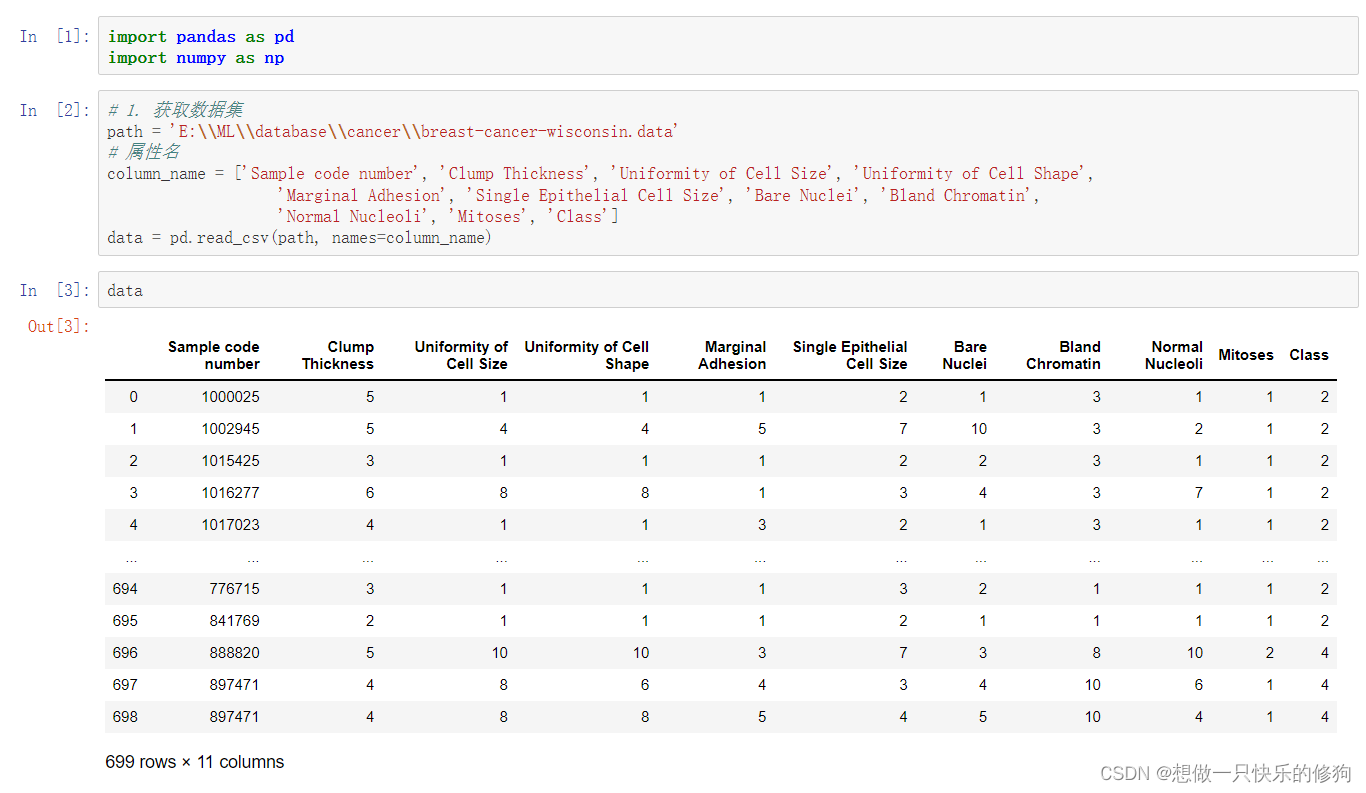
数据标准化(Normalization):在机器学习和数据分析领域,数据标准化是一种预处理技术,目的是将不同尺度或单位的特征转换到同一尺度下,以便于算法理解和处理。在本文的语境中,数据标准化是对肿瘤医学特征进行处理的过程,通过计算每个特征值与该特征所有样本均值之间的差值,再除以标准差,从而使得处理后的数据具有零均值和单位方差,这种标准化方法也称为z-score标准化。
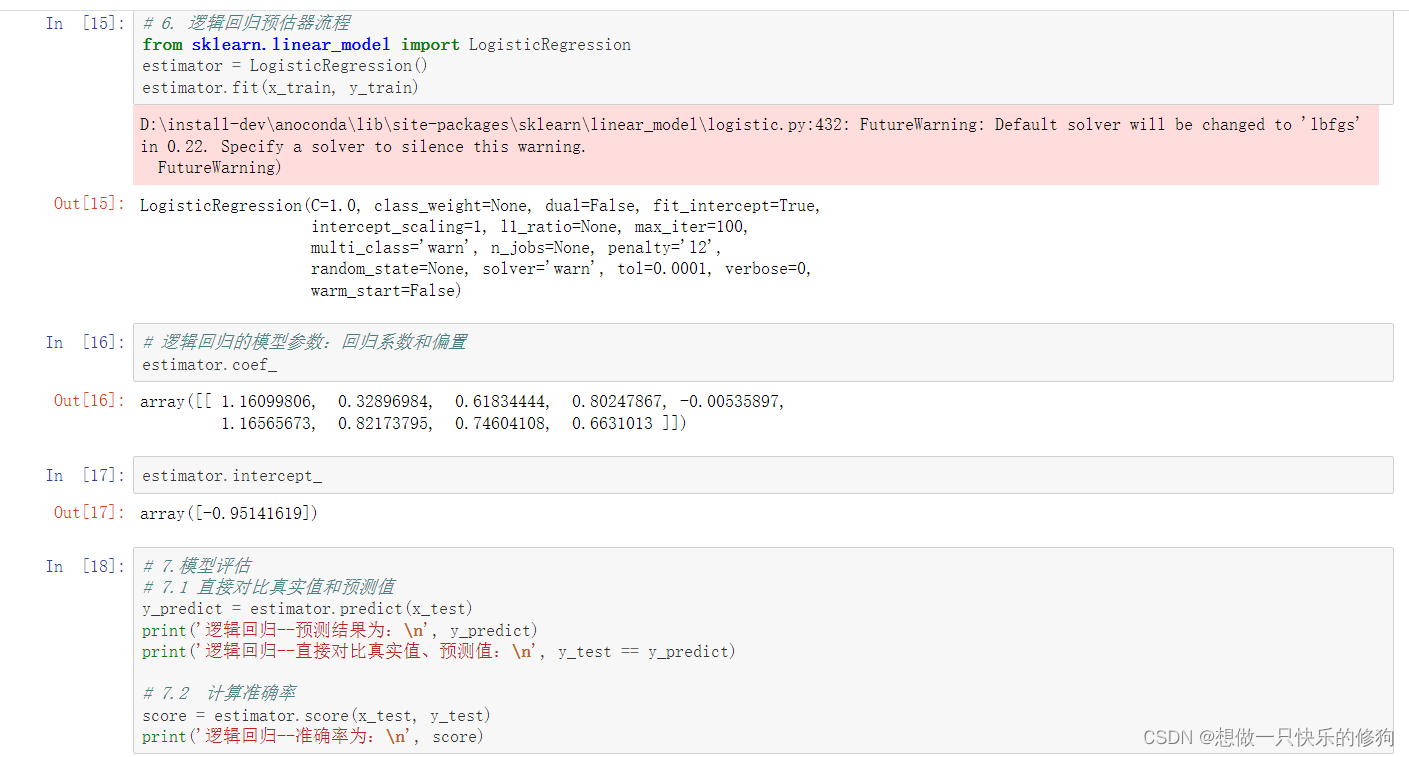
逻辑回归(Logistic Regression):逻辑回归是一种统计学和机器学习中的分类模型,尽管名字中包含“回归”,但它主要应用于二分类问题,也可以扩展到多分类问题。在文中提到的场景下,逻辑回归被用作预测肿瘤类型的预估器,它基于输入的肿瘤医学特征估计样本属于某一特定肿瘤类型的概率。
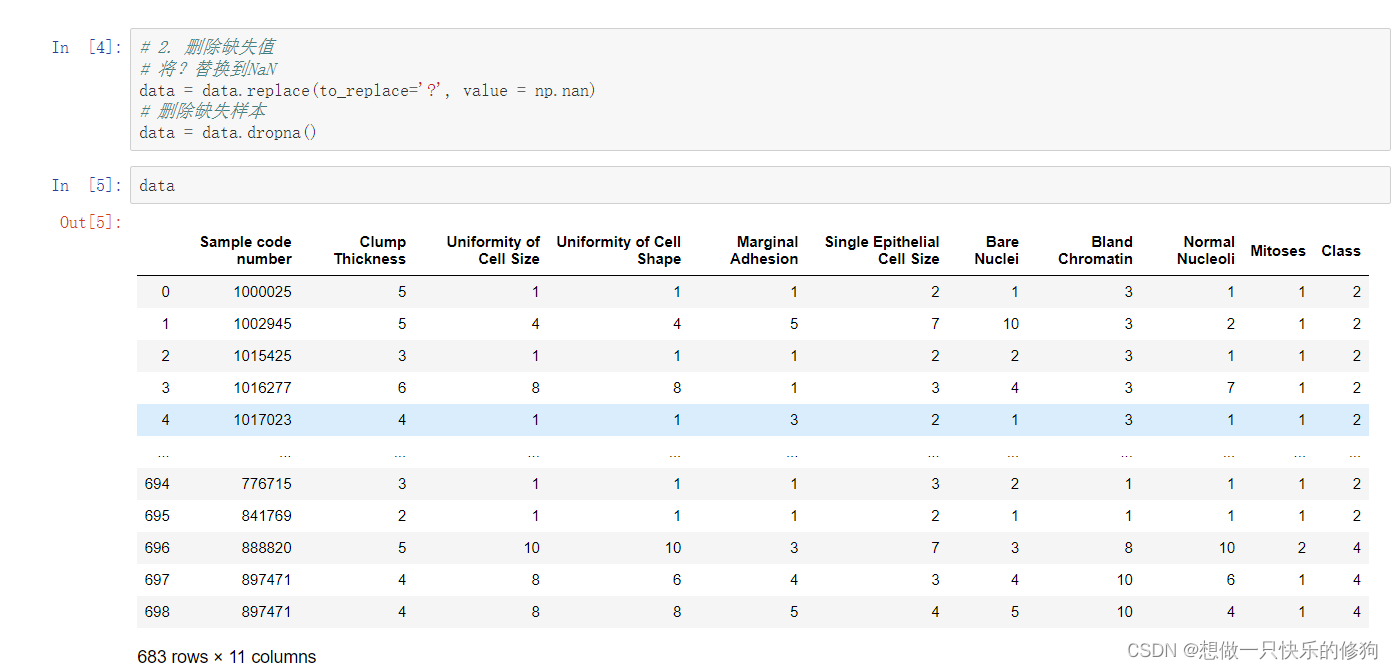
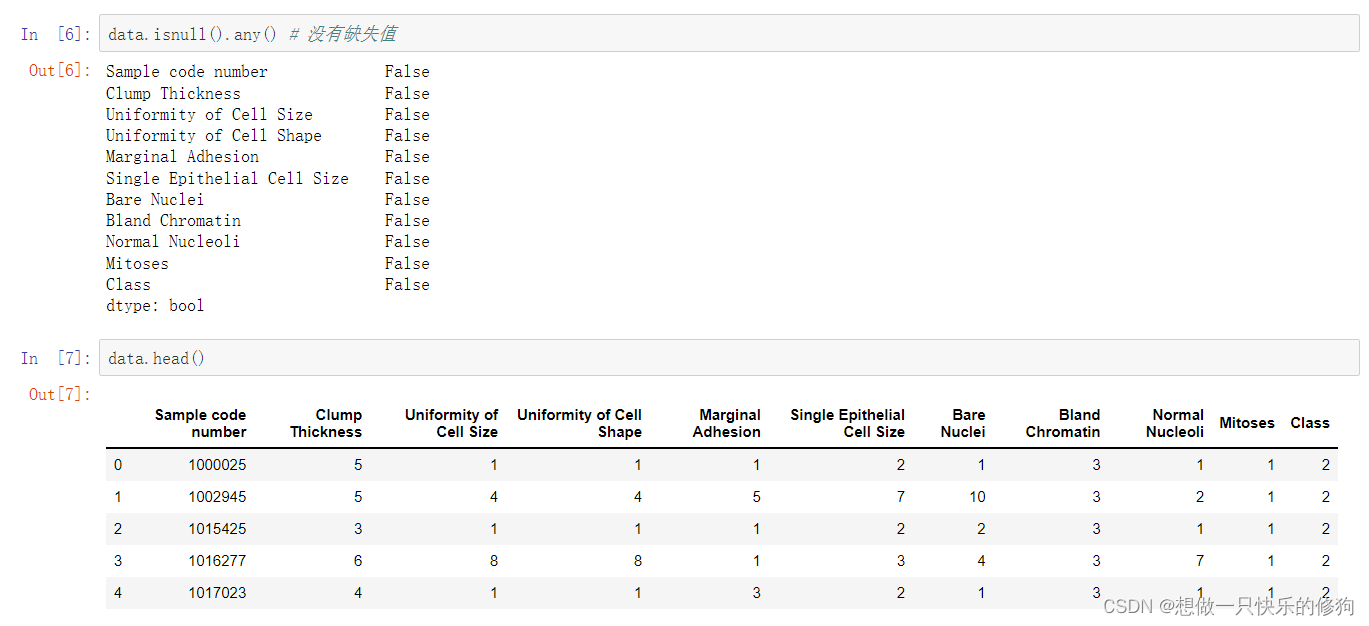
缺失值处理(Missing Value Handling):在数据挖掘和机器学习过程中,经常遇到数据集中某些观测值缺失的情况。缺失值处理是指采取一定的策略对这些缺失的数据进行填充、插补或者删除等操作,以确保后续分析的准确性和完整性。在本文讨论的数据集中,有16个缺失值用“?”表示,这意味着在进行数据分析之前,需要采用合适的方法来处理这些缺失的医学特征信息。可能的处理方式包括平均值填充、中位数填充、最近邻插补或使用专门的插补算法等。
延伸阅读
作为当前文章的延伸阅读,仅对当前文章有效。
在对UCI肿瘤数据集进行逻辑回归分析后,进一步的延伸阅读可聚焦于以下几个方面:
1. 最新医学研究进展:近期,《Nature Medicine》发表的一项研究表明,通过深度学习算法结合基因组学和转录组学数据,科学家们能够更精准预测癌症类型及预后。这不仅展示了大数据与AI技术在肿瘤诊断领域的潜力,也为未来改进和优化基于逻辑回归等传统机器学习方法提供新的启示。
2. 医疗数据分析的伦理考量:随着人工智能在医疗数据分析中的广泛应用,数据隐私保护和患者权益问题愈发凸显。《Science》最近的一篇报道探讨了如何在确保数据安全性和匿名性的同时,最大化利用医疗数据提升疾病预测准确率,这对于理解并合理应用包括UCI肿瘤数据集在内的公开资源具有现实指导意义。
3. 特征工程的重要性:针对肿瘤数据集的特征处理,一篇由《Machine Learning in Medicine》发布的论文详述了特征选择、缺失值填充、标准化等各种预处理技术对模型性能的影响,并强调了深入理解医学背景知识对于有效特征工程设计的关键作用。
4. 逻辑回归模型的局限与改进:尽管逻辑回归在许多分类任务中表现良好,但面对高维、非线性或多重共线性的医学数据时可能存在局限。《Journal of Machine Learning Research》上有一篇文章介绍了集成学习、神经网络以及梯度提升机等更复杂模型如何克服这些问题,提高肿瘤预测的准确性和泛化能力。
综上所述,围绕肿瘤数据集的分析与建模,读者可以关注最新的科研成果以了解前沿动态,同时思考数据伦理、特征工程的具体实践以及模型优化的可能性,不断拓宽视野,深化对机器学习在肿瘤研究领域应用的理解。
1. 最新医学研究进展:近期,《Nature Medicine》发表的一项研究表明,通过深度学习算法结合基因组学和转录组学数据,科学家们能够更精准预测癌症类型及预后。这不仅展示了大数据与AI技术在肿瘤诊断领域的潜力,也为未来改进和优化基于逻辑回归等传统机器学习方法提供新的启示。
2. 医疗数据分析的伦理考量:随着人工智能在医疗数据分析中的广泛应用,数据隐私保护和患者权益问题愈发凸显。《Science》最近的一篇报道探讨了如何在确保数据安全性和匿名性的同时,最大化利用医疗数据提升疾病预测准确率,这对于理解并合理应用包括UCI肿瘤数据集在内的公开资源具有现实指导意义。
3. 特征工程的重要性:针对肿瘤数据集的特征处理,一篇由《Machine Learning in Medicine》发布的论文详述了特征选择、缺失值填充、标准化等各种预处理技术对模型性能的影响,并强调了深入理解医学背景知识对于有效特征工程设计的关键作用。
4. 逻辑回归模型的局限与改进:尽管逻辑回归在许多分类任务中表现良好,但面对高维、非线性或多重共线性的医学数据时可能存在局限。《Journal of Machine Learning Research》上有一篇文章介绍了集成学习、神经网络以及梯度提升机等更复杂模型如何克服这些问题,提高肿瘤预测的准确性和泛化能力。
综上所述,围绕肿瘤数据集的分析与建模,读者可以关注最新的科研成果以了解前沿动态,同时思考数据伦理、特征工程的具体实践以及模型优化的可能性,不断拓宽视野,深化对机器学习在肿瘤研究领域应用的理解。
知识学习
实践的时候请根据实际情况谨慎操作。
随机学习一条linux命令:
umount /mnt
- 卸载已挂载的目录。
推荐内容
推荐本栏目内的其它文章,看看还有哪些文章让你感兴趣。
2023-02-18
2023-08-07
2023-09-10
2024-01-12
2023-01-11
2023-10-22
2023-01-13
2023-10-29
2024-01-09
2023-08-26
2023-01-02
2023-05-10
历史内容
快速导航到对应月份的历史文章列表。
随便看看
拉到页底了吧,随便看看还有哪些文章你可能感兴趣。
时光飞逝
"流光容易把人抛,红了樱桃,绿了芭蕉。"